 В предыдущей статье шла речь о установке, настройке и монтировании NFS шары с параметрами по умолчанию. Сейчас можно немного улучшить производительность как со стороны сервера, так и клиентской части. Но хочу заметить, что в зависимости от конфигурации и оборудования те же параметры могут и ухудшить производительность NFS.
В предыдущей статье шла речь о установке, настройке и монтировании NFS шары с параметрами по умолчанию. Сейчас можно немного улучшить производительность как со стороны сервера, так и клиентской части. Но хочу заметить, что в зависимости от конфигурации и оборудования те же параметры могут и ухудшить производительность NFS.
Конфигурация сервера:
- CPU: 16 cores (32 threads)
- RAM: 64GB
- Network: 4 x 1 Gbit
Улучшать будем в три этапа:
- Общее для клиента и сервера
- Серверная часть
- Клиентская часть
1 Общее для клиента и сервера
1.1 Параметры ядра
Первым делом подправим настройки ядра для улучшения производительности как с клиентской, так и с серверной стороны. Есть такая штука как буфер сокета. Такой буфер есть на входящие и исходящие запроси. Так как RPC запросов на запись и считывание может быть много, и если CPU или диск не успевает все обработать, то мы храним все запросы в маленькой очереди сокета, чтобы не потерялись. Из документации по ядру:
- rmem_default (The default setting of the socket receive buffer in bytes)
- rmem_max (The maximum receive socket buffer size in bytes)
- wmem_default (The default setting (in bytes) of the socket send buffer)
- wmem_max (The maximum send socket buffer size in bytes)
Размер буфера будем выставлять в соотношении 1 MiB на каждый 1 GB оперативной памяти. Нужные параметры выставляются следующим образом.
root@nfs:~# sysctl -w net.core.rmem_default=67108864 или root@nfs:~# echo 67108864 > /proc/sys/net/core/rmem_default root@nfs:~# sysctl -w net.core.rmem_max=67108864 или root@nfs:~# echo 67108864 > /proc/sys/net/core/rmem_max root@nfs:~# sysctl -w net.core.wmem_default=67108864 или root@nfs:~# echo 67108864 > /proc/sys/net/core/wmem_default root@nfs:~# sysctl -w net.core.wmem_max=67108864 или root@nfs:~# echo 67108864 > /proc/sys/net/core/wmem_max
Таким образом размер буфера сокетов обновиться в реальном времени (на лету). Чтобы параметры сохранились после ребута, нужно добавить их в автозагрузку.
root@nfs:~# cat /etc/sysctl.conf … net.core.wmem_max = 67108864 net.core.rmem_max = 67108864 net.core.wmem_default = 67108864 net.core.rmem_default = 67108864 …
Также нужно увеличить общую очередь всех входящих пакетов, UDP и TCP буфер для всех сокетов. Из документации ядра:
- udp_mem
Vector of 3 INTEGERs: min, pressure, max (in pages). Number of pages allowed for queueing by all UDP sockets.
min: Below this number of pages UDP is not bothered about its memory appetite. When amount of memory allocated by UDP exceeds this number, UDP starts to moderate memory usage.
pressure: This value was introduced to follow format of tcp_mem.
max: Number of pages allowed for queueing by all UDP sockets.
Defaults are calculated at boot time from amount of available memory.
- tcp_mem
Vector of 3 INTEGERs: min, pressure, max (in pages).
min: below this number of pages TCP is not bothered about its memory appetite.
pressure: when amount of memory allocated by TCP exceeds this number of pages, TCP moderates its memory consumption and enters memory pressure mode, which is exited when memory consumption falls under «min».
max: number of pages allowed for queueing by all TCP sockets.
Defaults are calculated at boot time from amount of available memory.
- netdev_max_backlog
Maximum number of packets, queued on the INPUT side, when the interface receives packets faster than kernel can process them.
tcp_mem и udp_mem измеряется в страницах памяти. Размер одной страницы – 4096 байт. По умолчанию, он большой, но можно увеличить на 10-20%, а netdev_max_backlog можно увеличить в 3 раза.
root@nfs:~# sysctl -w net.ipv4.udp_mem="1549836 2066449 3099672" или root@nfs:~# echo “1549836 2066449 3099672” > /proc/sys/net/ipv4/udp_mem root@nfs:~# sysctl -w net.ipv4.tcp_mem="1549836 2066449 3099672" или root@nfs:~# echo “1549836 2066449 3099672” > /proc/sys/net/ipv4/tcp_mem root@nfs:~# sysctl -w net.core.netdev_max_backlog=3000 или root@nfs:~# echo 3000 > /proc/sys/net/core/netdev_max_backlog
Т.е. min = 1549836 pages = 1549836 x 4096 byte = 6348128256 byte = ~5.9 GB.
После, нужно добавить все в автозагрузку. После чего, мы должны получить следующею картину.
root@nfs:~# cat /etc/sysctl.conf … net.core.wmem_max = 67108864 net.core.rmem_max = 67108864 net.core.wmem_default = 67108864 net.core.rmem_default = 67108864 net.ipv4.udp_mem = "1549836 2066449 3099672" net.ipv4.tcp_mem = "1549836 2066449 3099672" net.core.netdev_max_backlog = 3000 …
1.2 Сетевой стек
1.2.1 Ring buffer (Driver queue)
Рассмотрим схему сетевого стека, которую мы будем улучшать (рис. 1), чтобы понять, как вообще происходить передача данных через сетевую карту. Между IP стеком (IP stack) и контроллером сетевой карты располагается “очередь драйвера” (Driver queue). Что также называют FIFO ring buffer. В этой очереди хранятся указатели на упомянутые выше буферы сокетов ядра (SKB), которые в свою очередь уже хранят сами пакетные данные. В IP стеке в свою очередь храниться очередь IP пакетов. Аппаратный драйвер опустошает очередь IP стека и по шине данных отправляет информацию через NIC дальше. Driver queue – это простая first-in, first-out очередь где все запросы идут и обрабатываются последовательно (в принципе, что и должна делать сетевая карта быстро и просто). Но между IP стеком и этой очередью есть еще специальный слой для управления трафиком (Queueing discipline – Qdisc), а именно:
- классификация
- приоритетность
- рейт
Здесь как раз выставляются биты TOS. Тюнить его мы не будем, но это тоже возможно.
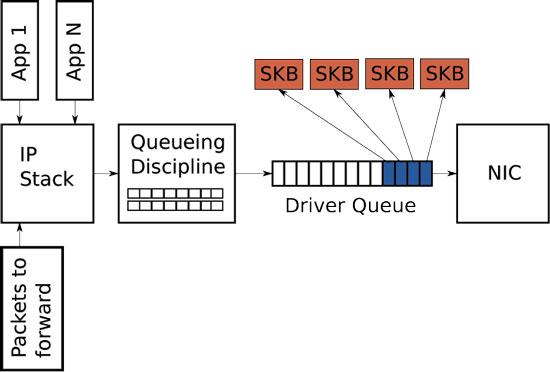
Рисунок 1 — Схема сетевого стека
В нашем случаи будет тюниться очередь драйвера. Его максимальный и поточный размер можно узнать следующим образом.
root@nfs:~# ethtool -g eth0 Ring parameters for eth0: Pre-set maximums: RX: 4096 RX Mini: 0 RX Jumbo: 0 TX: 4096 Current hardware settings: RX: 256 RX Mini: 0 RX Jumbo: 0 TX: 256
Это означает, что драйвер этой сетевой карты может держать в очереди не больше 4096 SKB-дескрипторов. Этот параметр нужно улучшать, если NIC драйвер не поддерживает BQL(Byte Queue Limits). BQL появился начиная с ядра 3.3 для автоматического вычисления размера очереди драйвера. BQL тюнить не надо, его максимальный лимит можно узнать следующим образом.
root@nfs:~# find /sys/ -name 'byte_queue_limits' root@nfs:~# cat cat /sys/devices/pci0000:00/0000:00:1c.0/0000:06:00.0/net/eth0/queues/tx-0/byte_queue_limits/limit_max 1879048192
Как видно, это 1.8GB (этот параметр измеряется уже в байтах).
Для случаев, когда нет поддержки BQL, очередь драйвера улучшается следующим способом.
root@nfs:~# ethtool -G eth0 tx 4096 root@nfs:~# ethtool -G eth1 tx 4096 root@nfs:~# ethtool -G eth2 tx 4096 root@nfs:~# ethtool -G eth4 tx 4096 root@nfs:~# ethtool -G eth0 rx 4096 root@nfs:~# ethtool -G eth1 rx 4096 root@nfs:~# ethtool -G eth2 rx 4096 root@nfs:~# ethtool -G eth4 rx 4096
Тут было улучшено очередь для всех сетевых интерфейсов по входящему и исходящему трафику.
1.2.2 MTU
Как мы знаем, у сетевых карт есть максимальный размер передаваемого блока данных (MTU). По умолчанию он становит 1500 байт. Если на уровни приложений какой-то апликейшн отправляет пакет размером 5КB в буфер сокета, то ІР стеку этот пакет нужно будет разбить на 4 IP пакета и передать на сетевую карту через очередь драйвера (т.е. 1500 х 4 = 6КВ и 1КВ лишних данных). Чтобы избежать данного overhead-a в линуксе имплементировано:
- TCP segmentation offload (TSO)
- UDP fragmentation offload (UFO)
- Generic segmentation offload (GSO)
Посмотреть значение этих параметров можно так:
root@nfs:~# ethtool -k eth0 | grep -E 'tcp-segmentation-offload|udp-fragmentation-offload|generic-segmentation-offload' tcp-segmentation-offload: on udp-fragmentation-offload: off [fixed] generic-segmentation-offload: on
Все это позволяет ІР стеку создавать пакеты размер которых превышает MTU (IPv4 maximum = 65536 байт) и добавить их в очередь драйвера, где уже самой NIC карте предоставляется роль разбиения пакетов на нужный размер. И в этом случаи мы можем ей помочь, увеличив размер MTU используя Jumbo Frames до 9КВ.
root@nfs:~# ifconfig eth0 mtu 9000 root@nfs:~# ifconfig eth1 mtu 9000 root@nfs:~# ifconfig eth2 mtu 9000 root@nfs:~# ifconfig eth3 mtu 9000
Данные команды увеличат размер MTU до 9000. Теперь проверяем новый размер MTU и также добавляем изменения в настройку интерфейсов.
root@nfs:~# netstat -i | awk '{print $1,$2}'
Kernel Interface
Iface MTU
eth0 9000
eth1 9000
eth2 9000
eth4 9000
root@nfs:~# vim /etc/network/interfaces
...
iface xxx inet static
...
mtu 9000
...
...
Но хочу заметить, что если сервер соединен с клиентом через сетевой свитч/роутер, то Jambo frames должен также быть включен на сетевом оборудовании, иначе возникнут проблемы с сетью.
2 Серверная часть
Чисто серверная часть заключается в улучшении NFSd плис предыдущие все настройки ядра и сети. Исходя из Solaris NFS Server Performance and Tuning Guide for Sun Hardware количество nfsd демонов (потоков) должно быть равным:
- 2 на каждый активный клиентский процесс
- 16-32 на каждый серверный CPU
- 16 на 10 Мбит-ную или 160 на 100 Мбит-ную сеть
Добавить nfsd демонов можно следующими способами (20 nfsd/CPU).
root@sto:~# rpc.nfsd 640 root@sto:~# echo 640 > /proc/fs/nfsd/threads root@sto:~# vim /etc/default/nfs-kernel-server … RPCNFSDCOUNT=640 …
Первые две команды добавят nfsd процессов на лету (в реальном времени) без перезагрузки nfsd демона. Последняя команда добавить конфигурацию для автостарта nfsd, чтобы применить эту настройку, нужно перезагрузить nfsd демон.
3 Клиентская часть
На клиентской стороне можно проводить манипуляцию с опциями монтирования плюс все настройки ядра и сети из пункта 1 этой статьи.
В предыдущей статье мы уже проводили монтирование NFS шары с описанием опций. В данном случаи мы добавим только те опции, которые помогут улучшить производительность.
root@client:~# mount -o rw,soft,nfsvers=3,intr,bg,timeo=100,retrans=8,rsize=1048576,wsize=1048576 sto:/data01 /mnt/sto
Все эти флаги описаны в предыдущей статье. Если коротко, здесь мы монтируем NFS v3 шару в режиме soft с интервалом таймаута запросов в 10 секунд с 8-ю попытками подключения до сервера. Максимальный размер для NFS запросов на считывания и записи становит 1048576 (1MiB).
Если используется Jambo Frames, то rsize и wsize можно поставить 9000 байт, и тогда каждый клиентский NFS запрос будет передаваться по сети без фрагментации.
Хочу заметить, что даже если вы указали в опциях монтирования самый большой размер для запросов, то при монтировании, ядро само обрежет до максимального, который оно может поддерживать.
root@client:~# cat /proc/mounts | grep sto sto:/data01 /mnt/sto nfs rw,relatime,vers=3,rsize=65536,wsize=65536,namlen=255,soft,proto=tcp,timeo=100,retrans=8,sec=sys,mountaddr=sto,mountvers=3,mountport=47879,mountproto=udp,local_lock=none,addr=x.x.x.x 0 0 или root@client:~# nfsstat -m
Манипуляции с timeo и retrains (увеличивать значения) нужно проводить если вы получаете ошибки вида:
kernel: nfs: server < system name > not responding, timed out
Или видите, что retrans счетчик начал стремительно расти:
root@client:~# nfsstat -rc Client rpc stats: calls retrans authrefrsh 281447039 12930 281455555
На этом все. В следующей статье пойдет речь о мониторинги и логировании в NFS.